

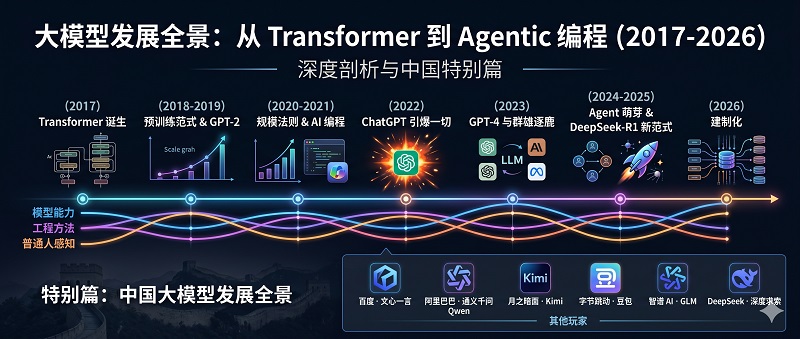
从 Transformer 到 Agentic Engineering——一部关于智能进化的编年史
主线:时间序关键里程碑
隐藏脉络:模型能力进化 · 工程方法论 · 普通人感知
特别章节:中国大模型发展全景参考来源:Wikipedia、学术论文、Karpathy 演进框架、网络搜索
目录
脉络总览图
第一阶段:奠基期(2017–2019)
2017:Transformer 诞生
2018:预训练范式的确立
2019:危险的能力
第二阶段:突破期(2020–2021)
2020:规模法则的震撼
2021:AI 编程元年
第三阶段:爆发期(2022)
2022 年前半:对齐与推理的突破
2022.11.30:ChatGPT 引爆一切
第四阶段:群雄逐鹿(2023)
2023 上半年:GPT-4 与开源觉醒
2023 下半年:平台化与百模大战
第五阶段:深水区(2024)
推理模型与"System 2 思维"
Agent 的萌芽
第六阶段:新范式(2025)
DeepSeek-R1:AI 的斯普特尼克时刻
Agentic 编程的全面崛起
第七阶段:建制化(2026)
隐藏脉络·三条线索深度分析
脉络一:模型能力跃迁路径
脉络二:工程方法论的进化
脉络三:普通人的感知曲线
特别篇:中国大模型发展全景
概览:中国 AI 六小虎与巨头的牌桌
百度 · 文心一言
阿里巴巴 · 通义千问 Qwen
月之暗面 · Kimi
字节跳动 · 豆包
智谱 AI · ChatGLM / GLM
DeepSeek · 深度求索
其他重要玩家
中国大模型行业的独特逻辑
附录:关键数字记忆
脉络总览图
2017 ─── Transformer 诞生(基础架构奠基)
2018 ─── GPT-1 / BERT(预训练范式确立)
2019 ─── GPT-2("危险"的生成能力,伦理讨论升温)
2020 ─── GPT-3(规模法则验证,few-shot 惊艳学术界)
2021 ─── Copilot / Codex(AI 编程元年)
2022 ─── ChatGPT(引爆公众认知,AI 全民化)
2023 ─── GPT-4 / 开源爆发 / 中国入局(多模态+生态战)
2024 ─── GPT-4o / o1 / Claude 3.5(推理突破+工具使用)
2025 ─── DeepSeek R1 / Agentic / MCP(成本革命+工程化)
2026 ─── Agent 规模化 / 建制化(基础设施化)
第一阶段:奠基期(2017–2019)
2017年 · Transformer 诞生
2017 年 6 月,Google 的八位研究者——Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan Gomez、Łukasz Kaiser、Illia Polosukhin——在 NeurIPS 会议上发表了一篇只有 15 页的论文:《Attention Is All You Need》。
这篇论文提出的 Transformer 架构,以"自注意力机制"(Self-Attention)取代了此前统治 NLP 领域二十年的 RNN/LSTM。它做到了三件事:
解决了长序列建模问题:RNN 读第 1000 个词时已经"忘记"第 1 个词;Transformer 的注意力机制让每个词都能直接"看到"序列中的任意位置
实现了并行化训练:RNN 必须一个词一个词地串行处理;Transformer 可以整句并行计算,训练效率产生数量级飞跃
提供了一种统一架构:同一套 Transformer 既可以做编码(理解),也可以做解码(生成)
传统 RNN: Transformer:
"我" → "爱" → "你" "我" ←→ "爱"
(必须依次处理) ↘ ↙ ↘
"你"
(所有词同时交互)
当时没有人想到,这个架构会成为此后十年一切 AI 突破的地基。GPT、BERT、Claude、Gemini、DeepSeek……所有叫得出名字的大模型,都是 Transformer 的后代。
🔬 能力突破:从"统计模型"到"上下文理解",机器第一次真正"读懂"了句子
⚙️ 工程突破:并行训练取代串行——同样的算力,训练速度快了一个数量级
👤 公众感知:零。这是纯学术界的狂欢
2018年 · 预训练范式的确立
如果说 2017 年发明了引擎,2018 年则是两派人马分别用这台引擎造出了两辆截然不同的车。
6 月,OpenAI 发布 GPT-1。
论文标题《Improving Language Understanding by Generative Pre-Training》奠定了此后一切 GPT 系列的方法论:
海量无标注文本 → 预训练(学习语言的统计规律)
↓
下游任务标注数据 → 微调(适配具体任务)
GPT-1 只有 1.17 亿参数,以今天标准"小得可怜",但它的核心理念是革命性的:不需要为每个任务从头训练模型,一个预训练好的基础模型可以适配几乎所有 NLP 任务。
GPT-1 使用了 Decoder-only(仅解码器)架构——它只用了 Transformer 的右半部分,这让它天然擅长"生成"而非"理解"。
10 月,Google 发布 BERT。
BERT(Bidirectional Encoder Representations from Transformers)走了另一条路:Encoder-only(仅编码器)。它用了一种叫"掩码语言模型"(Masked Language Model)的训练方法——随机遮住句子中的一些词,让模型根据上下文猜出被遮住的词。
输入: "我 [MASK] 吃 [MASK]"
BERT: "我 [想] 吃 [饭]" ← 根据上下文双向推断
GPT: "我想吃" → "饭" ← 单向预测下一个词
BERT 的 3.4 亿参数虽然不是天文数字,但它在发布时横扫了 11 项 NLP 基准测试——情感分析、命名实体识别、问答、文本蕴含……每一项都被刷新到前所未有的高度。
BERT 和 GPT 的路线分歧,决定了两家公司此后十年的技术走向:
BERT(Encoder-only)→ 擅长理解、分类、抽取 → Google 搜索的核心能力
GPT(Decoder-only)→ 擅长生成、创作、对话 → OpenAI 的护城河
事实证明,历史选择了 GPT 的路线。到 2023 年,学术界的 BERT 使用率开始大幅下降——因为 Decoder-only 模型通过"提示"就能完成原来需要微调 Encoder 才能做的事。
🔬 能力突破:从静态词向量到上下文感知的动态表示——"苹果"是水果还是公司,模型看上下文就知道
⚙️ 工程突破:预训练-微调范式确立,成为此后数年的行业标准流程
👤 公众感知:NLP 圈震动,工业界开始关注但还没大规模落地
2019年 · "危险"的能力
2 月,OpenAI 发布 GPT-2。 15 亿参数,是 GPT-1 的 10 倍以上。
按照惯例,OpenAI 应该直接开源模型权重和代码。但他们做了一个震惊业界的决定:分阶段发布。 先只放出最小的 1.24 亿参数版本,最大版本推迟了 9 个月才放出。
理由是:"这个模型太危险了。"
GPT-2 可以生成极其连贯的长文本——新闻、故事、技术文档,真假难辨。OpenAI 担心它会被用来:
大规模生产假新闻
冒充他人撰写内容
制造垃圾信息淹没真实资讯
这个决定在当时引发了激烈争论。支持者认为这是负责任的 AI 安全实践;反对者(包括许多研究者)认为这是在制造恐慌、炒作营销,而且"不开源反而让坏人先研发出更强的模型"。
无论动机如何,GPT-2 的"危险论"客观上把 AI 安全问题推到了公众视野。这是第一次,非技术媒体用头版报道"AI 可能会写假新闻"。
10 月,另一件影响深远的事发生了:Google 将 BERT 应用于英文搜索。这意味着大模型第一次进入了 10 亿级用户的消费产品。你搜一个长尾问题,Google 不再只是匹配关键词,而是真正"理解"了你的意图再返回结果。
到 12 月,BERT 已经覆盖了 Google 搜索的 70 多种语言;到 2020 年 10 月,几乎每一个英文查询都经过了 BERT 处理。这是大模型第一次在商业上证明自己的价值——不是以"酷炫 demo"的方式,而是静悄悄地提升了全球数十亿人的搜索体验。
🔬 能力突破:GPT-2 的文本生成从"勉强通顺"跨越到"以假乱真";BERT 让搜索从"关键词匹配"进化到"语义理解"
⚙️ 工程突破:"分阶段发布"成为 AI 安全讨论的标准议题;模型规模竞赛正式拉开序幕
👤 公众感知:GPT-2"危险论"登上主流媒体标题,普通人第一次听说了"AI 写假新闻"这个概念。但这个阶段的 AI 仍然是"新闻里的东西",不是"我能用的东西"
第二阶段:突破期(2020–2021)
2020年 · 规模法则的震撼
5 月,OpenAI 发布 GPT-3。 1750 亿参数——是 GPT-2 的 100 倍以上,也是当时世界上最大的语言模型。
但参数数量本身不是重点。重点是 GPT-3 展现了一种前所未有的能力:Few-Shot Learning(少样本学习)。
简单说:你不需要给 GPT-3 几千个训练样本让它学会一个新任务。你只需要在提示词(Prompt)里给它几个例子,它就能"理解"任务要求并完成。
传统方式(需要微调):
给模型 10,000 个"英文→法文"翻译样本 → 训练 → 模型学会翻译
GPT-3 方式(Few-Shot Prompting):
提示词里放 3 个翻译例子 →
"English: I love you. French: Je t'aime." →
GPT-3 直接开始翻译
这种 涌现能力(Emergent Ability)是规模法则(Scaling Law)的产物——2020 年 1 月,Jared Kaplan 等 OpenAI 研究者在论文《Scaling Laws for Neural Language Models》中系统性地证明:模型的性能随着参数数量、训练数据量和计算量的增加而可预测地提升。 这不是线性增长——当模型跨过某个规模的临界点后,某些能力会突然"涌现"出来。
GPT-3 就是这个临界点的产物。它能写诗、写代码、做翻译、写邮件、做摘要,甚至能进行简单的数学推理——所有这些都是通过"提示"完成的,不需要任何额外训练。
OpenAI 没有开源 GPT-3,而是通过 API 的形式提供访问。这确立了一种新的商业模式:模型即服务(Model-as-a-Service)。开发者按 token 付费调用,OpenAI 负责模型的运行和维护。
同时,"提示词工程"(Prompt Engineering)这个概念诞生了——如何设计提示词以获得最佳输出,成为一门新"手艺"。
6 月,GitHub 与 OpenAI 合作推出 GitHub Copilot 技术预览——基于 GPT-3 的代码专用版本 Codex。在 IDE 中输入注释描述意图,Copilot 就能自动生成代码。AI 辅助编程的大门被推开了一条缝。
🔬 能力突破:Few-Shot Learning 涌现——模型开始表现出"举一反三"的能力。规模不再是量变,而是质变
⚙️ 工程突破:API 化商业模式确立;"Prompt Engineering"概念出现;Scaling Law 成为指导模型研发的核心理论
👤 公众感知:科技圈被 GPT-3 震撼——"它能写诗!它能写代码!"但普通人仍然隔着一层纱,因为 GPT-3 只在 API 和少数内测产品中可用
2021年 · AI 编程元年
这是 AI 从"实验室"走向"IDE"的一年。
6 月,GitHub Copilot 正式发布。 基于 OpenAI Codex,它直接嵌入 VS Code、JetBrains 等主流 IDE。程序员写代码时,Copilot 在后台实时建议下一行代码、整个函数,甚至根据注释生成完整实现。
程序员输入: // 解析 CSV 文件,按第二列降序排序,返回前10行
Copilot 输出: def parse_csv_top10(filepath): ...
(完整实现,包括异常处理和边界条件)
这是开发者群体第一次大规模、日常化地接触大模型。Copilot 在程序员中迅速普及,到 2022 年 6 月已有超过 120 万付费用户。
程序员的反应是分裂的:
一部分人狂喜:"我的效率翻倍了"
一部分人焦虑:"AI 会不会取代我?"
一部分人质疑:"生成的代码质量靠谱吗?"
但无论如何,"AI 能不能写代码"这个问题已经有了明确答案——能。
1 月,OpenAI 发布 DALL·E——第一个引起广泛关注的文本到图像生成模型。虽然效果还比较粗糙,但它证明了 Transformer 架构不仅可以处理文本,还可以处理图像。"多模态"这个概念开始进入公众视野。
7 月,一家新公司 Anthropic 成立。 创始人是从 OpenAI 离开的 Dario Amodei(前研究 VP)和 Daniela Amodei。他们的核心理念是:AI 的发展必须以安全为前提。
这个分裂标志着一个持续至今的路线之争:能力优先 vs 安全优先。 OpenAI 以快速迭代、追求更强能力著称;Anthropic 以谨慎发布、强调"宪法 AI"(Constitutional AI)为特色。两家公司的竞争——既是技术路线之争,也是价值观之争——深刻塑造了此后数年的大模型产业格局。
🔬 能力突破:代码生成从"能写"到"好用";多模态从概念变成原型(DALL·E)
⚙️ 工程突破:Copilot 将大模型嵌入开发者工作流——"AI 辅助"找到了第一个大规模落地的场景
👤 公众感知:程序员群体被劈成两半——热爱者 vs 焦虑者。"AI 抢饭碗"的讨论第一次有了真实案例。普通大众仍然只在新闻里看到 AI,没有亲身体验
第三阶段:爆发期(2022)
2022年前半 · 对齐与推理的突破
2022 年上半年,三件重要的事悄然发生。当时看起来只是学术进展,回头看却是 ChatGPT 成功的三个技术支柱。
1 月,OpenAI 发布 InstructGPT。
InstructGPT 是 GPT-3 的改进版。技术上,它引入了一项名为 RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习) 的关键技术。流程如下:
Step 1: 让人工标注员写出"好的回答"→ 用这些数据微调模型(SFT)
Step 2: 让模型对同一个问题生成多个回答 → 标注员排序 → 训练奖励模型(RM)
Step 3: 用奖励模型通过强化学习优化语言模型(PPO)
效果是革命性的:InstructGPT 只有 13 亿参数,却在人类评测中击败了 1750 亿参数的 GPT-3。不是因为更"聪明",而是因为更"听话"——它学会了遵循人类的指令,而不是自顾自地生成文本。
这解决了大模型落地最关键的障碍:可控性。 一个很聪明但不听话的模型没有实用价值;一个足够聪明且听话的模型可以做成产品。
1 月,Google 发表 Chain-of-Thought(思维链)论文。
Jason Wei 等研究者在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中证明:如果在提示词中要求模型"一步步思考"(Let's think step by step),模型的复杂推理能力会大幅提升。
没有 CoT:
Q: "小明有5个苹果,吃了2个,又买了3个,现在有几个?"
A: "6个"(可能对,可能错,取决于模型大小)
有 CoT:
Q: "小明有5个苹果,吃了2个,又买了3个,现在有几个?请一步步思考。"
A: "小明开始有5个苹果。吃了2个后剩下3个。又买了3个,所以总共有6个。答案是6。"
(正确率大幅提升)
这个简单的技巧让大模型在数学推理、逻辑推理、常识推理等任务上的表现产生了质的飞跃。它揭示了:大模型的能力远超我们的使用技巧——不是模型不行,是我们还没学会怎么问。
夏天,Anthropic 完成 Claude 第一版训练。 但他们选择不发布,理由是"需要更多的内部安全测试"和"不想引发危险的 AI 军备竞赛"。Anthropic 的谨慎和 OpenAI 的激进,形成了鲜明对比。
与此同时,图像生成领域也在爆发:7 月 Midjourney 公测,8 月 Stable Diffusion 开源。人们第一次可以用自然语言生成高质量的图像。AI 的艺术创作能力让公众既震撼又不安——"AI 画的画算艺术吗?"
🔬 能力突破:RLHF 让模型从"聪明"进化到"听话+聪明";CoT 解锁了复杂推理能力
⚙️ 工程突破:RLHF 成为行业标准的对齐方法;"怎么让大模型遵循人类意图"从学术问题变成工程问题
👤 公众感知:大多数人还不知道这些技术突破——但暴风雨前的宁静即将结束
2022年11月30日 · ChatGPT 引爆一切
2022 年 11 月 30 日,OpenAI 发布 ChatGPT。 这是一个基于 GPT-3.5(InstructGPT 的升级版)的对话式 AI 产品。
没有新闻发布会,没有大规模营销。Sam Altman 只在推特上发了一条:"try ChatGPT"。
接下来的事情超出了所有人的预期:
5 天,用户突破 100 万
2 个月,月活用户突破 1 亿——成为史上增长最快的消费应用(TikTok 用了 9 个月,Instagram 用了 2.5 年)
2 个多月,微软追加投资 100 亿美元,并将其整合进 Bing、Office、Azure
为什么会爆得这么快?
第一,它是对话式的。 之前的 GPT-3 需要通过 API 调用,需要写 Prompt,有技术门槛。ChatGPT 打开网页就能聊天——任何会用键盘的人都能用。这彻底消除了使用门槛。
第二,它能做太多事了。 写邮件、写论文、写代码、写诗歌、翻译、总结、头脑风暴、角色扮演……用户发现 ChatGPT 几乎"什么都能聊"。每发现一个新用法,就在社交媒体上引发新一轮传播。
第三,它"像人"。 和 ChatGPT 对话的体验,与之前任何 AI 都不同。它会承认错误、会拒绝不当请求、会根据上下文调整回答风格。RLHF 让它变得"有礼貌"、"有分寸"——这反而让人感觉它更像一个"人"。
ChatGPT 的意义远超一款产品。 它是人类历史上第一次,普通人可以直接和"通用人工智能雏形"对话。它把 AI 从"新闻里的概念"变成了"我手上能用的工具"。全球数亿人第一次亲身体验到:AI 真的来了。
ChatGPT 引发的连锁反应:
科技行业: 每家公司紧急立项"大模型战略"
教育行业: 学生用 ChatGPT 写作业 → 学校禁 → 又解禁
内容行业: 媒体用 AI 写稿、设计师用 AI 出图
政府层面: ChatGPT封锁中国,引发国产替代
投资市场: AI 概念股爆发,一级市场 AI 投资激增
公众舆论: "AI 取代人类"从科幻话题变成社会讨论
🔬 能力突破:ChatGPT 本身没有新架构——它证明的是"RLHF + 对话界面 + 免费开放"的组合拳有多大的社会能量
⚙️ 工程突破:从"API 服务"到"消费产品"的跨越——OpenAI 学会了"做产品"
👤 公众感知:🔥🔥🔥 全民 AI 觉醒。几乎每个人的信息流都被 ChatGPT 占领。这是 AI 历史上最重要的"破圈"事件。从此,AI 不再是少数人的话题,而是全社会的焦点
第四阶段:群雄逐鹿(2023)
2023上半年 · GPT-4 与开源觉醒
2023 年是"大模型军备竞赛"全面爆发的一年。如果说 ChatGPT 点燃了一根火柴,2023 年则是整片森林都在燃烧。
1 月,Andrej Karpathy(特斯拉前 AI 总监、OpenAI 创始成员)发推:"The hottest new programming language is English."(最热门的编程语言是英语。)这句话精准概括了 AI 对编程的颠覆:自然语言正在成为新的编程界面。
2 月,微软发布 New Bing。 集成的是 GPT-4 的早期版本。搜索引擎第一次可以"对话"而不是"列链接"。虽然因为幻觉和诡异的对话上了新闻,但它标志着搜索范式的根本性改变已经拉开序幕。
2 月,Meta 发布 LLaMA。 参数从 7B 到 65B,仅在研究许可下发布。但很快模型权重在 4chan 泄露,全球研究者蜂拥而入。LLaMA 的泄露引爆了一场运动——开源大模型运动。
在 LLaMA 之前,开源社区面对 GPT-3/4 这样的闭源巨无霸几乎毫无还手之力。LLaMA 证明:一个精心设计的 7B 模型,在消费级硬件上就能跑出接近 GPT-3.5 的水平。这意味着大模型不再是少数巨头的专利。
3 月 14 日,OpenAI 发布 GPT-4。 这是又一个分水岭:
多模态:GPT-4 不仅能读文字,能"看懂"图片——图表、照片、手写笔记、截图
超强推理:在美国 BAR 律师资格考试中超过 90% 的考生;在 SAT 数学中接近满分;能通过几乎所有的 AP 考试
编程飞跃:在 LeetCode 困难题上表现优异;能根据手绘草图生成网页代码
GPT-4 给人的震撼不是"更好一点",而是"这个是另一个层次的东西"。如果说 GPT-3.5 是聪明的高中生,GPT-4 在某些领域已经接近专业级。
3 月,Anthropic 发布 Claude。 初始版本仅对少数获准用户开放 API。Claude 的差异化定位是"有帮助、无害、诚实"——安全和伦理是其核心卖点。
3 月 16 日,百度发布文心一言。 这是中国大厂的第一枪。虽然发布会上的演示视频是录播(股价因此大跌 6%),但它标志着中国大模型产业的正式起跑。
4 月,阿里巴巴发布通义千问。
中国大模型的"揭幕战"打响。
🔬 能力突破:GPT-4 的多模态理解——AI 第一次"看到"世界;LLaMA 证明开源也能很强
⚙️ 工程突破:搜索+AI 的融合实验(New Bing);开源生态的爆发(LLaMA 衍生出 Alpaca、Vicuna、Guanaco 等数十个微调版本)
👤 公众感知:GPT-4 的法律/医学/编程能力让专业人士感到威胁;中国用户开始关注国产大模型;"Prompt Engineer"成为 2023 年最热门的新兴岗位
2023下半年 · 平台化与百模大战
下半年,竞争从"谁的模型更强"扩展到"谁能让模型落地"。
7 月,Anthropic 发布 Claude 2(全面对外)。 100K token 的上下文窗口让长文档处理成为可能——一本《了不起的盖茨比》全书可以一次塞给 AI 分析。
7 月,Meta 发布 LLaMA 2(开源可商用)。 这是开源生态的真正转折点——可商用许可证意味着企业可以放心使用。HuggingFace 上的下载量爆炸式增长。
8 月 31 日,中国首批大模型通过备案向公众开放。 百度文心一言、字节豆包、商汤日日新等 8 家率先获批。中国用户终于可以合法使用国产大模型。
9 月,Mistral 发布 Mistral 7B。 这家法国创业公司证明:不需要千亿参数,精心设计的 7B 模型也能很强。欧洲在大模型竞赛中有了自己的位置。
11 月,OpenAI 首届开发者大会(DevDay)。 Sam Altman 宣布了一系列平台化举措:
GPT-4 Turbo:128K 上下文,价格降低 3 倍
Assistants API:开发者可以在 API 层面创建能使用工具的 AI Agent
GPT Store:用户可以创建、分享、销售自定义 GPT——"AI 时代的 App Store"
DevDay 的战略意图很清楚:OpenAI 要做大模型时代的"操作系统"和"应用商店"。
11 月 17–22 日,OpenAI 发生"政变"。 董事会在未提前通知的情况下罢免 CEO Sam Altman,理由是"对董事会不坦诚"。随后引发了一场惊心动魄的五天拉锯:
员工联名信——"不解雇董事会,我们就集体辞职"(770 名员工中 738 人签名)
微软表态支持 Altman(宣布将 Altman 和 Brockman 招入微软)
投资者施压
最终 Altman 复职,董事会重组
这场风波暴露了 OpenAI 治理结构的根本矛盾:非盈利董事会 vs 商业实体。也是对 AI 行业的一个警示——当技术能力超越组织治理能力时,危机不会来自模型,而会来自人。
12 月,Google 发布 Gemini 1.0。 原生多模态(从一开始就设计为处理文本+图像+音频+视频),分为 Ultra/Pro/Nano 三档。Google 开始全面反击。
12 月,Mistral 发布 Mixtral 8x7B。 采用 MoE(Mixture of Experts,混合专家)架构——每次推理只激活部分参数,用更少的计算量达到更大模型的性能。MoE 从学术实验变成产品级方案。
🔬 能力突破:上下文窗口从 4K → 128K → 100K token(从"读一段"到"读一本书");MoE 架构工程化
⚙️ 工程突破:OpenAI 的平台化(Assistants API + GPT Store)、MoE 架构普及、RAG(检索增强生成)成为企业落地标配、中国"百模大战"全面爆发
👤 公众感知:ChatGPT 封锁中国IP → 国产替代加速;"AI 取代工作"的讨论从程序员扩展到设计师、翻译、客服;OpenAI 的 5 天宫斗剧成为全球头条;企业端从"要不要用 AI"变成"怎么用 AI"
第五阶段:深水区(2024)
GPT-4o 与"全模态"体验
2024 年,竞争的维度从"模型能力"扩展到"交互体验"和"工具使用"。
1 月,GPT Store 上线。 虽然生态热度不如预期(多数 GPT 是低质量的提示词包装),但它开创了"AI 应用市场"的概念。
2 月,Google 发布 Gemini 1.5 Pro。 杀手级特性:100 万 token 上下文窗口。可以一次性处理 1 小时视频、11 小时音频、或 70 万字的文本。Google 用这个特性宣告:搜索起家的公司在信息处理上仍有独特优势。
3 月,Anthropic 发布 Claude 3。 三档策略(Opus/Sonnet/Haiku)确立了"不同任务用不同模型"的产品思路:
Opus:最强能力,最贵最慢——用于复杂分析、深度写作
Sonnet:平衡型——日常编程、对话的主力
Haiku:最快最便宜——简单任务、实时响应
Claude 3 Opus 在多项基准测试上首次超越了 GPT-4。这是第一次有非 OpenAI 模型在综合能力上登顶。
4 月,Meta 发布 LLaMA 3(8B/70B)。 开源模型的质量逼近闭源旗舰。对于大多数企业场景,"开源 70B"已经足够好。
5 月 13 日,OpenAI 发布 GPT-4o("o" for "omni")。 这是交互体验的革命:
原生多模态:文本、语音、视觉不再是三个模型拼接,而是一个模型同时处理
实时语音对话:延迟降低到毫秒级,可以自然打断——像跟真人说话一样
情感感知:能捕捉语气、情绪、环境音
GPT-4o 发布于 Google I/O 大会前一天,精准狙击了 Google 的发布节奏。这种做法本身就说明:AI 竞争的激烈程度已经不亚于智能手机战争。
6 月,Anthropic 发布 Claude 3.5 Sonnet。 编程能力质的飞跃——在 SWE-bench(真实 GitHub 问题修复基准)上的表现远超所有竞品。"谁是最好的 AI 程序员"成为最受关注的战场。
6 月,Anthropic 发布 Artifacts 功能。 AI 对话的输出不再只是文本——可以在侧边栏直接生成并运行代码、交互式图表、SVG 图形。这是从"聊天"到"协作创作"的跨越。
用户: "用 React 做一个番茄钟"
Claude: [生成完整的前端代码]
→ 侧边栏直接渲染、可交互
🔬 能力突破:100 万 token 上下文、原生全模态融合、实时语音对话
⚙️ 工程突破:三档模型分层策略成为行业标配;AI 从"聊天"走向"交互式产出"
👤 公众感知:"AI 会说话、能看、能听懂"——科幻电影成了现实;"最好的 AI 程序员"成为社交媒体热议话题;开发者开始用 Artifacts 快速做原型
推理模型与"System 2 思维"
2024 年下半年的最大突破,来自一个看似矛盾的方向:让 AI "慢"下来。
9 月 12 日,OpenAI 发布 o1(代号"Strawberry")。 这不是一个"更大"的模型,而是一个"更会思考"的模型。
传统 LLM 的工作方式:
你问 → 它马上回答(一个 token 接一个 token)
o1 的工作方式:
你问 → 它在内部"思考"几十秒甚至几分钟 → 它回答
↑
这个"思考"是隐藏的 Chain-of-Thought——
它自己跟自己对话,分析问题、尝试方案、纠正错误
效果令人震撼:
在国际数学奥林匹克(IMO)资格考试中排名前 500
在 Codeforces 编程竞赛中超过 89% 的参赛者
在博士级科学问题上达到专家水平
Daniel Kahneman 在《思考,快与慢》中将人类思维分为两套系统:
System 1:快速、直觉、自动("2+2=4")
System 2:缓慢、理性、需要努力("17×24=?")
传统 LLM 一直只在做 System 1。o1 第一次让 AI 展现出了 System 2 的雏形——不是"知道答案",而是"推导出答案"。
10 月,Anthropic 发布 Claude "Computer Use"。 AI 可以"看"屏幕、"移动"鼠标、"敲击"键盘——像人一样操作电脑。虽然还很慢且容易出错,但方向明确:AI 不只是回答问题,AI 要"干活"。
12 月,OpenAI 发布 o3(跳过了 o2 以避免与英国电信运营商 O2 的商标冲突)。 推理能力再次跃升。ARC-AGI 基准(测试 AI 的抽象推理能力)上得分从 GPT-4 的接近零提升到 o3 的 87.5%(人类水平为 85%)。
年底,DeepSeek 发布 DeepSeek-V3。 训练成本仅为约 $550 万,不到 GPT-4 训练成本的 1/20,性能却接近 GPT-4o。这个消息在年末的 AI 圈悄悄传播——多数人还没有意识到这意味着什么。
🔬 能力突破:从 System 1 到 System 2——AI 学会了"深思熟虑"而不是"脱口而出"
⚙️ 工程突破:推理时计算(Test-time Compute)成为新的 Scaling 方向——不再只堆训练算力,推理时多算几步也能提升
👤 公众感知:o1 的推理能力让公众第一次感受到 AI "真的在思考"——不只是模式匹配;"AI 取代人类推理"的讨论升温
第六阶段:新范式(2025)
DeepSeek-R1:AI 的斯普特尼克时刻
1957 年,苏联发射了人类第一颗人造卫星斯普特尼克 1 号。美国人震惊地发现:他们在太空竞赛中落后了。 这个时刻引发了其后十年的科技追赶浪潮。
2025 年 1 月 20 日,中国公司 DeepSeek 发布了 DeepSeek-R1。
DeepSeek-R1 是一个开源推理模型,在数学、编程、科学推理上的表现正面对标 OpenAI o1。但它的发布带来了两个炸裂性信息:
训练成本极低:DeeSeek-V3 的训练成本约 557 万,而 GPT-4 估计超过1 亿——差了近 20 倍。即使在同等性能的情况下,也意味着此前"大模型必须烧钱"的共识被推翻
完全开源(MIT 许可证):任何人都可以下载、使用、修改、商用
市场反应是毁灭性的:英伟达股价单日暴跌 17%,市值蒸发近 6000 亿美元——创下美股历史上最大的单日市值损失。投资者开始重估:如果训练大模型不需要买那么多 GPU,那英伟达的天价估值还合理吗?
DeepSeek 的聊天机器人迅速登顶美国 App Store 下载榜——一个中国 AI 应用在美国消费市场登顶,这本身就是一个标志性事件。
DeepSeek-R1 的核心意义:
打破"中国 AI 落后美国 2-3 年"的叙事
证明"低成本 + 开源"路线可行,动摇了 OpenAI 的闭源高成本模式
催化了全球范围的开源推理模型浪潮
👤 公众感知:DeepSeek-R1 是全球性冲击。不只是科技圈——普通人也在讨论"中国 AI 超过美国了?"民族自豪感与全球震惊交织。
Agentic 编程的全面崛起
2025 年是"Agent"这个概念从口号变成产品的一年。
2 月,Andrej Karpathy 提出"Vibe Coding"(氛围编程)。
定义:"你完全放弃对代码的控制,只是描述你想要的,AI 生成一切。你不在乎代码长什么样——只要它能跑。"
Vibe Coding:
用户:"帮我做一个笔记应用,要支持 Markdown 和标签分类"
AI: [生成完整的前后端代码] → [部署] → [返回链接]
用户:用了觉得不错,"再加一个暗黑模式"
AI: [自动修改代码] → 搞定
Karpathy 的宣言引发了持久讨论:
支持者:编程民主化了——不懂代码也能做软件
质疑者:复杂的生产级应用不可能"vibe"出来
务实派:原型和工具可以用 Vibe Coding,核心系统不行
2 月,Anthropic 发布 Claude Code(CLI 工具)。 开发者可以在终端直接用自然语言让 AI 完成编程任务——读代码、写代码、运行测试、修复 Bug、提交 PR。
Claude Code 的范式意义在于:AI 不再是"副驾驶"(Copilot),而是"可以独立完成任务的 Agent"。
$ claude "分析这个 repo 的性能瓶颈,优化后提交 PR"
Claude Code:
→ 自动搜索代码库
→ 定位热点函数
→ 生成优化方案
→ 执行修改
→ 运行基准测试
→ 提交 PR
(全程自主,人只需要审查最终结果)
6 月,Karpathy 提出"Context Engineering"(上下文工程)。 核心洞察:影响 AI 产出的最关键因素不是提示词怎么措辞,而是 AI 在推理时"看到"了什么信息。
这标志着思维方式的转变:
Prompt Engineering: "怎么说" → 怎么措辞、怎么引导
Context Engineering: "给什么" → 给哪些文件、什么规范、哪些历史信息
9 月,ChatGPT 支持 MCP(Model Context Protocol)。 MCP 是 Anthropic 提出的开放协议,定义了 AI Agent 如何与外部工具和数据源通信。ChatGPT 对 MCP 的支持意味着:AI 的"接口标准"正在形成。
如果有过 TCP/IP 协议统一了互联网通信的历史比较,MCP 可能有类似的潜力——让不同的 AI Agent、工具、数据源用同一种语言通信。
10 月,OpenAI 发布 ChatGPT Atlas(AI 浏览器)。 AI 公司下场做浏览器——不只是回答问题,而是控制用户的信息入口。浏览器大战 2.0 拉开序幕。
11 月,Karpathy 提出"Spec Coding"(规格编程)。 用规格(Specification)驱动 AI 编码:先定义清晰的需求规格、验收标准、约束条件,然后让 AI 根据规格自主生成代码。人从"执行者"变成"定义者和验收者"。
12 月,Anthropic 收购 Bun(JavaScript 运行时)。 一家 AI 公司为什么要收购 JS 运行时?因为 Claude Code 运行代码慢了,收购 Bun 可以让代码执行快 10 倍。AI 公司开始收购基础设施——这是 2000 年代 Google 自建数据中心的现代翻版。
2025 年末的格局:
OpenAI:最强闭源推理(o3),最强消费生态(9亿周活 ChatGPT)
Anthropic:最强编程 Agent(Claude Code),估值 $380B
Google:最强上下文窗口(Gemini),基础设施无敌(TPU)
DeepSeek:最强"性价比",开源路线旗帜
Meta:开源生态最大贡献者(LLaMA),自用(推荐系统)
🔬 能力突破:推理模型全面成熟、AI Agent 从概念走向产品、开源推理首次对标闭源最强
⚙️ 工程突破:Agentic Engineering 元年、MCP 标准确立、上下文工程取代提示词工程、复利工程方法论出现
👤 公众感知:DeepSeek-R1 带来民族自豪感+全球震惊;"Vibe Coding"让不懂编程的人也能做 App;"Agent"成为年度热词;AI 公司的天价估值成为日常
第七阶段:建制化(2026)
2026 年进入本文撰写的"现在"。大模型行业从"群雄逐鹿"进入"建制化"阶段。
2 月,Karpathy 提出"Agentic Engineering"(智能体工程)。 这是他对 AI 编程范式思考的集大成:
"不是你写代码,不是 AI 写代码,而是你指挥 AI 完成一系列有明确目标的任务——你负责架构决策和质量验收,AI 负责执行和实现。"
Agentic Engineering 的核心要素:
SPEC 驱动:每个任务都有明确的规格说明和验收标准
多 Agent 协作:不同的子 Agent 负责不同环节(设计、编码、测试、审查)
验收内建:每个步骤完成后自动验证,不符合标准则自动修复或人工介入
知识沉淀:每次任务完成后将经验固化为可复用的 Skill
2 月,Anthropic 在超级碗投放 AI 广告。 超级碗广告是美国消费品的最高殿堂。Anthropic 的广告展示了 Claude 如何帮助普通人处理生活和工作中的问题。这意味着:AI 公司已经开始像可口可乐和耐克一样做品牌营销。
2 月,ChatGPT 周活跃用户达到 9 亿——接近全球互联网用户的 1/6。ChatGPT 已经成为基础设施。
3 月,Anthropic 成立 Anthropic Institute。 一个专门研究 AI 政策的智库。AI 公司从"做技术的"变成"定规则的"。
4 月,Deepseek 发布 V4 Pro(1.6T MoE,100 万上下文),V4 Flash(284B,100 万上下文,快速推理)。V4 与 GPT-5.5 发布仅间隔1天,DeepSeek 已经在和 OpenAI 正面对标。
3 月,Claude 推出手机 Agent。 用户可以通过手机发送指令,让 Claude 操作电脑上的程序。AI 开始具备跨设备的操作能力。
5 月,Anthropic 拒绝美国国防部要求。 国防部要求 Anthropic 移除合同中关于"禁止将 AI 用于国内监控和全自主武器"的限制。Anthropic 拒绝了。随后被国防部列入黑名单。AI 军事化的伦理冲突公开化。
5 月,Anthropic 与马斯克的 xAI 达成云合作。 使用 xAI 的"Colossus 1"数据中心来扩展模型训练能力。AI 基础设施的规模已经从"GB/核心"进入到"GW/平方公里"的级别。
⚙️ 工程突破:Agentic Engineering 标准化、AI 基础设施 GW 级、治理建制化
👤 公众感知:AI 超级碗广告——AI 已是主流消费品;AI 军事伦理成为公众讨论——"终结者"不再只是电影
隐藏脉络 · 三条线索深度分析
脉络一:模型能力跃迁路径
2017 ──────────→ 2020 ──────────→ 2022 ──────────→ 2024 ──────────→ 2025 ─────→ 2026
│ │ │ │ │ │
Transformer GPT-3 规模法则 RLHF + CoT 多模态原生融合 推理模型 多Agent
(架构基础) (涌现能力) (对齐+推理) (全模态) (System 2) (协作)
│ │ │ │ │ │
"能读懂" "能生成" "能对话" "能看能听" "能思考" "能干活"
六大跃迁的详细拆解:
跃迁 1:2017 · Transformer("能读懂")
从统计 n-gram 到自注意力 → 理解上下文
RNN 最大有效序列 ~100 词;Transformer 无理论上限
训练从串行变并行 → 规模成为可能
跃迁 2:2020 · GPT-3 175B("能生成")
规模越过临界点 → Few-Shot Learning 涌现
不需要训练样本就能执行新任务
生成的文本从"看得出是机器"到"难以分辨"
跃迁 3:2022 · RLHF + CoT("能对话")
RLHF:从能力强到"听话+强"
CoT:从"直接回答"到"一步步推理"
对话式交互成为主要界面
跃迁 4:2024 · GPT-4o("能看能听")
文本/语音/视觉不是三个模型拼接,而是一个模型原生理解
实时对话延迟降至人类对话水平
情感感知让交互更自然
跃迁 5:2024-2025 · o1/R1 推理模型("能思考")
System 2 思维:"多想想再回答"
推理时计算取代训练时计算成为新 Scaling 维度
AI 第一次展现出"深思熟虑"而非"脱口而出"
跃迁 6:2025-2026 · Agent 化("能干活")
从"回答问题"到"执行多步任务"
Computer Use:AI 能操作电脑
多 Agent 协作:任务分解、并行执行、结果合并
脉络二:工程方法论的进化
大模型从"论文里的算法"到"生产环境的工程系统",经历了六代工程范式的演进:
2018: 预训练+微调(Pretrain → Fine-tune)
"训一个通用模型,再用标记数据适配具体任务"
代表人物:Jacob Devlin(BERT 一作)、Alec Radford(GPT-1/2 一作)
↓
2020: Prompt Engineering(提示词工程)
"不需要微调,设计好 Prompt 就能让模型完成任意任务"
代表人物:Tom B. Brown(GPT-3 一作)、Riley Goodside(首位"提示词工程师")
↓
2022: RLHF + RAG(对齐 + 知识外挂)
"让模型听话 + 让模型访问外部知识库"
代表人物:Long Ouyang(InstructGPT 一作)、Paul Christiano(RLHF 先驱)、Patrick Lewis(RAG 一作)、Harrison Chase(LangChain 创始人)
↓
2023: 平台化 + MoE 工程化
"AI 作为 API/App Store + 用更少算力做更大模型"
代表人物:Sam Altman、Arthur Mensch(Mistral CEO)、Noam Shazeer(MoE 论文一作)
↓
2024: 推理时计算 + 模型分层战略
"多花时间推理比多花钱训练更划算 + 不同场景用不同模型"
代表人物:Mark Chen(OpenAI 研究 SVP)、Dario Amodei、Mike Krieger
↓
2025: Agentic Engineering + MCP + 上下文工程 + 复利工程
"AI 自主执行任务 + AI 之间的通信标准 + 上下文管理 + 每次开发沉淀知识"
代表人物:Andrej Karpathy、Mike Krieger、Harrison Chase、梁文锋
↓
2026: 多 Agent 编排 + 基础设施化 + 建制化治理
"多 Agent 协同工作 + GW 级算力 + AI 行业规则制定"
代表人物:Andrej Karpathy、梁文锋Karpathy 的五阶段范式演进(这是一条非常有洞察力的思维主线):
三个工程层次(层层嵌套):
Harness Engineering(系统级:约束、验证、纠正)
⊃ Context Engineering(信息层:AI 看到什么)
⊃ Prompt Engineering(指令层:怎么问)
Prompt Engineering:你告诉马"往前走"、"停下来"——控制最基本的行为
Context Engineering:你给马看地图和路标,告诉它路线——它能理解更复杂的任务
Harness Engineering:你给马套上缰绳和马鞍,设定围栏——你可以可靠地驾驭它完成长途任务
脉络三:普通人的感知曲线
感知强度
↑
┌─────┤ ██ Agentic 日常化
│ │ ████
│ │ ████ DeepSeek 冲击
│ │ ████
│ │ ████ GPT-4 震撼
│ │ ████
│ │ ████ ChatGPT 全民化
│ │ ████
│ ████ GPT-2 危险论
│██
└─────┼──────┼──────┼──────┼──────┼──────┼──────→ 时间
2017 2019 2020 2022 2023 2025 2026
各阶段公众心态的定性描述:
2017–2019:无感期
普通人对大模型的存在完全无知
AI 仍然是"机器人"、"自动驾驶"这类实体 AI 的代名词
媒体偶有报道(AlphaGo),但公众认为"离我很远"
标志性话语:不存在——因为没人讨论
2020–2021:猎奇期
GPT-3 的 Demo 在科技媒体刷屏
"AI 能写诗"成为轻度谈资
Copilot 让程序员群体第一次接触 LLM
大部分普通人仍然无感
标志性话语:"AI 写的东西还挺像样子的"
2022.11 后:全民 AI 觉醒期
ChatGPT 两个月破亿——堪比 TikTok 的社会渗透
每个行业都在讨论"AI 会取代我吗"
学生用 ChatGPT 写作业引发教育系统震荡
标志性话语:"你试过 ChatGPT 了吗?"
2023 年中:焦虑与兴奋交织期
"Prompt Engineer 年薪百万"的招聘信息刷屏
"AI 取代程序员"成为年度技术圈话题
ChatGPT 被中国封锁——加速国产替代
标志性话语:"AI 会不会取代我的工作?"
2024:日常化期
AI 变成工作流中的工具,而非新闻话题
程序员默认使用 Copilot/Cursor/Claude Code
o1 的推理让公众感受"AI 真的在思考"
标志性话语:"用 AI 帮我想想这个方案"
2025 初:地缘政治冲击期
DeepSeek-R1 引爆全球——"中国 AI 超越美国"
英伟达暴跌 17% 登上财经版头条
"Vibe Coding"让完全不懂编程的人开始做 App
标志性话语:"DeepSeek 比 ChatGPT 还强?"
2025 中至今:理所当然期
Agent 成为日常——"让 AI 去处理"
AI 超级碗广告——AI 和可口可乐一个级别
ChatGPT 周活 9 亿——每 6 个网民里就有 1 个在用
标志性话语:"这个让 Agent 去做就好了"
特别篇:中国大模型发展全景
如果说全球大模型的历史是一道主菜,中国大模型的发展就是其中最浓墨重彩的一章。从追随到并跑,再到在某些维度上实现超越——这段历史只有 3 年,却浓缩了技术追赶、地缘博弈、商业竞争的全部戏剧性。
概览:中国 AI 六小虎与巨头的牌桌
2023-2025 年,中国大模型产业形成了 "3 巨头 + 6 创业公司" 的格局:
┌──────────────────────────────────────────────────────┐
│ 中国大模型牌桌 │
├──────────────────────────────────────────────────────┤
│ │
│ 三大巨头(有云、有场景、有资金): │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 百度 │ │ 阿里 │ │ 字节 │ │
│ │ 文心一言 │ │ 通义千问 │ │ 豆包 │ │
│ │ (ERNIE) │ │ (Qwen) │ │ (Seed) │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ │
│ 六小虎(独立创业公司): │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 智谱 AI │ │ 月之暗面 │ │ MiniMax │ │
│ │ GLM/Z.ai │ │ Kimi │ │ Hailuo │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 百川智能 │ │ 零一万物 │ │ DeepSeek │ │
│ │ Baichuan │ │ Yi/01.AI │ │ 深度求索 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ + 科大讯飞(星火)、商汤(日日新)、腾讯(混元)等 │
└──────────────────────────────────────────────────────┘
百度 · 文心一言
"起了大早,赶了晚集"的先行者。
百度是中国最早投入 AI 的互联网巨头。文心(ERNIE)系列模型的研发始于 2019 年,远早于 ChatGPT 的出现。ERNIE 的核心技术特色是"知识增强"——在预训练中融入知识图谱,让模型更好地理解中文语境中的实体关系。
关键节点:
2023.03.16:文心一言发布(邀请测试)。发布会用了录播而非实时 Demo,导致百度港股当日暴跌 6%。Robin Li 后来承认:"如果早知道 ChatGPT 会这么火,我们一定会更早发布"
2023.08.31:作为首批获批向公众开放的大模型,文心一言正式上线
2023.10:发布 ERNIE 4.0,号称在中文理解上超越了 GPT-4
2023.12:用户突破 1 亿
2024.04:用户突破 2 亿;6 月突破 3 亿
2024.09:中文名从"文心一言"改为"文小言",定位转向搜索助手
2025.03:发布 ERNIE 4.5 和推理模型 ERNIE X1;4 月发布 Turbo 版(更快更便宜)
评价:百度拥有中国最扎实的 AI 技术积累(搜索引擎的 NLP 需求是天然的练兵场),但在产品化和用户心智上,被后来者(豆包、DeepSeek)反超。文心一言的困境折射出百度整体面临的挑战——有技术,无产品。
阿里巴巴 · 通义千问 Qwen
"开源战略的最佳实践者。"
阿里的通义千问(Qwen)系列走出了与众不同的路——以开源为核心战略,用生态包围商业。
关键节点:
2023.04:通义千问 Beta 发布
2023.09:正式向公众开放
2023.12:开源 Qwen-72B 和 Qwen-1.8B
2024.06:发布 Qwen2 系列,多尺寸覆盖(0.5B 到 72B),部分开源
2024.11:发布 QwQ-32B-Preview(推理模型,对标 o1)——Apache 2.0 开源。这是全球首个开源推理模型,比 DeepSeek-R1 早了两个月
2025.01:发布 Qwen2.5-VL(视觉语言模型),3B/7B/32B/72B 四个尺寸
2025.03:发布 Qwen2.5-Omni-7B(全模态模型)——"一个模型搞定文本+图像+音频+视频"
2025.04.28:发布 Qwen3 系列——全部 Apache 2.0 开源
2026.02:发布 Qwen3.5 和 Qwen3.5-Plus
评价:Qwen 是开源社区中仅次于 LLaMA 的"第二选择",在某些中文和代码任务上甚至更优。阿里通过"顶级开源模型 + 云服务变现"的模式,在商业和社区之间找到了独特的平衡。Qwen 系列是阿里在 AI 时代最具战略价值的产品之一。
月之暗面 · Kimi
"长文本之王"到"推理猛兽"。
月之暗面(Moonshot AI)由清华系创业者杨植麟于 2023 年 3 月创立。杨植麟是 AI 领域的新星——Transformer-XL 和 XLNet 的作者之一。
Kimi 的差异化路线非常清晰:长上下文。
关键节点:
2023.03:公司成立
2023.10:发布 Kimi 聊天机器人,支持 20 万汉字上下文(当时全球最长)
2024.02:阿里领投 10 亿美元,估值 $25 亿
2024.03:上下文升级至 200 万汉字——一本《三体》全书可以一次塞进去
2024.08:月活用户排名中国第三;腾讯投资,估值 $33 亿
2025.06:月活排名下滑至第七——被豆包等竞品挤压
2025.07:开源 Kimi K2(1 万亿总参数,MoE 架构),是全球参数最大的开源模型之一
2025.09:发布 Kimi-K2-Instruct-0905,Agentic 编码能力大幅提升,上下文扩展至 256K
2025.11:发布 Kimi K2 Thinking,开源推理模型
2026.01:发布 Kimi K2.5(多模态升级),性能超越三款美国顶级模型
评价:Kimi 从"长文本"这个单点突破切入,建立了用户心智。K2 的开源策略(1 万亿参数级)标志着中国创业公司在大模型开源上的最高水准。杨植麟的学术背景让 Kimi 在技术深度上保持了独特的优势。
字节跳动 · 豆包
"用流量和低价碾压一切。"
豆包是字节跳动旗下的 AI 助手,底层模型来自字节的 AI 团队。豆包的策略是典型的字节风格:大规模投放 + 极低定价 + 场景全覆盖。
关键节点:
2023.08:豆包作为首批获批应用向公众开放
2024.05:字节大幅下调豆包 API 价格,引发中国大模型"价格战"——百万 token 输入仅需 0.8 元,远低于行业平均
2024 下半年:豆包成为中国月活最高的 AI 应用,超越文心一言和 Kimi
2025:豆包持续迭代,在代码、多模态、长文本等方向跟进
评价:豆包的成功体现了中国大模型市场的独特逻辑——流量和场景比技术更重要。 字节有抖音的流量池、有成熟的用户增长方法论、有做消费产品的基因。豆包的技术可能不是最强的,但用户量和商业变现可能是最多的。它的低价策略直接改变了中国大模型的定价体系,迫使所有玩家跟进。
智谱 AI · ChatGLM / GLM
"学院派的开源先锋。"
智谱 AI 脱胎于清华大学 KEG 实验室,2019 年成立,2025 年国际品牌更名为 Z.ai。核心产品是 GLM(General Language Model)系列。
智谱最大的差异化是技术路线:GLM 使用自研的"自回归填空"(Autoregressive Blank Infilling)训练算法,不同于纯粹的 Decoder-only 或 Encoder-only。
关键节点:
2019:公司成立(清华孵化)
2022.05:发表 GLM 训练算法论文
2023:发布 ChatGLM 系列对话模型,迅速成为中文开源社区首选
2024.03:宣布研发 Sora 级视频生成技术
2024.05:沙特 Prosperity7 投资,估值 ~$30 亿
2024.10:发布 GLM-4-Voice(端到端语音大模型)
2025.01:被美国列入实体清单
2025.04:全面转向 MIT 开源许可;启动 IPO 准备
2025.07:发布 GLM-4.5 和 GLM-4.5 Air,国际品牌更名为 Z.ai
2025.08:GLM 模型宣布兼容华为昇腾芯片
2025.09:发布 GLM-4.6——使用纯国产芯片训练(寒武纪等)
2026.01:在港交所上市
2026.03:发布 GLM-5.1
评价:智谱是中国大模型公司中技术底色最纯粹的之一。它的 GLM 技术路线独立于 GPT 范式,体现了技术自信。被美国列入实体清单后,智谱加速了"去 NVIDIA 化"——GLM-4.6 用国产芯片训练是一个标志性事件。
DeepSeek · 深度求索
"硅谷最怕的中国公司。"
DeepSeek 的故事需要更多篇幅,因为它是 中国 最重要的 AI 故事——没有之一。
起源:量化交易的"意外之子"
DeepSeek 的母公司是幻方量化(High-Flyer),一家中国顶级对冲基金。创始人梁文锋(Liang Wenfeng)是 AI 技术的狂热信徒——幻方从 2016 年就开始用 GPU 集群做量化交易,到 2021 年 AI 已经驱动了其全部交易决策。
关键背景:
2016:幻方量化成立,梁文锋开始用深度学习做交易
2019:幻方建造第一个 GPU 集群"Fire-Flyer 1"——1,100 张 GPU,耗资 2 亿元
2021:梁文锋开始大量购买 NVIDIA A100 GPU,在美国芯片禁令前囤积了约 10,000 张
2021:"Fire-Flyer 2"开始建设——5,000 张 A100,625 个节点,预算 10 亿元
2022:Fire-Flyer 2 的 GPU 使用率达 96%,年运行 5,674 万 GPU 小时
2023:DeepSeek 的诞生
2023.04:幻方宣布成立 AGI 研究实验室
2023.07:实验室独立为 DeepSeek 公司
2023.11:发布 DeepSeek Coder 和 DeepSeek-LLM 系列
2024:快速迭代
2024.01:发布 DeepSeek-MoE(MoE 架构)
2024.05:发布 DeepSeek-V2(MoE 架构,236B 总参数,21B 激活)
2024.06:DeepSeek-Coder V2
2024.09:DeepSeek V2.5
2024.11:DeepSeek-R1-Lite 预览版上线
2024.12:发布 DeepSeek-V3(671B MoE 参数,37B 激活)
DeepSeek-V3 的训练成本震惊业界:仅 557 万。作为对比,GPT-4 的训练成本估计超 1 亿,Meta 的 LLaMA 3.1 估计数千万美元。
2025.01.20:全球震动——DeepSeek-R1
DeepSeek-R1 在数学、编程、科学推理上正面对标 OpenAI o1
完全开源(MIT 许可证)
训练成本仅为 OpenAI 的零头
登顶美国 App Store 下载榜
导致英伟达单日暴跌 17%(市值蒸发约 $5,890 亿)
2025:下半年
2025.08.21:发布 DeepSeek V3.1(MIT 开源),引入混合架构——同一模型支持"思考模式"与"非思考模式"自由切换。在 SWE-bench 和 Terminal-bench 等基准上超越 V3 和 R1 达 40% 以上
2025.09.22:V3.1-Terminus 更新
2025.09.29:发布 V3.2-Exp,采用自研的 DeepSeek 稀疏注意力机制(DeepSeek Sparse Attention),进一步降低推理成本
2026:V4——万亿参数时代的开源旗舰
2026.04.24:发布 DeepSeek-V4 系列预览(MIT 开源)
DeepSeek-V4-Pro:1.6 万亿参数(MoE 架构),100 万 token 上下文窗口
DeepSeek-V4-Flash:2,840 亿参数,100 万 token 上下文窗口,快速推理
V4 被 华为和寒武纪(Cambricon) 等中国芯片厂商正式采用,成为国产芯片生态的基础模型
V4 发布与 OpenAI GPT-5.5(4 月 23 日)仅隔一天——时间节奏上 DeepSeek 已与 OpenAI 同步
同期,DeepSeek 启动首次外部融资:约 3 亿美元,估值约 $100 亿
为什么 DeepSeek 能做到?
芯片囤积 + 禁令倒逼创新:在美国芯片禁令前囤积了大量 A100,禁令后倒逼出极致的效率优化。不能用最新 GPU?那就把软件写到极致
MoE 架构的精妙应用:671B 总参数,每次只激活 37B——"大模型的脑子,小模型的消耗"
MLA(Multi-head Latent Attention):自研的注意力机制优化,大幅降低推理成本和显存占用
蒸馏技术的战略使用:用大模型的知识蒸馏到小模型,保持高质量的同时降低成本
没有商业包袱:背靠量化基金,无需短期内商业化,可以纯粹追求技术极致
DeepSeek 的 CEO 梁文锋曾说:"我们不关心 ChatGPT 做了什么,我们关心用户需要什么,以及怎么用最少的资源做到最好。"这种工程师文化 + 量化交易的数学底蕴 + 芯片禁令的"创造性压力",三者的化学反应产生了 DeepSeek 这个"异类"。
评价:DeepSeek 的意义超越了技术。它证明了 "资源约束可以催生创新"——不一定需要最多的 GPU,用更聪明的算法也可以做出世界级模型。它动摇了"AI 是富国游戏"的叙事。它也是中国 AI 行业最响亮的一次回答:不是模仿,是超越。
其他重要玩家
除"六小虎+巨头"外,中国大模型生态中还有几个值得关注的名字:
科大讯飞 · 星火
2023.05 发布,主打语音交互和教育场景
讯飞在语音技术上有 20 年积累,星火在语音理解和生成上有独特优势
MiniMax
2021.12 由商汤前员工创立
产品路线独特:AI 伴侣 Talkie 在海外下载榜排名靠前;Hailuo AI 做文本/音乐/视频生成
2024.03 阿里领投 25 亿
2026.01 港交所上市
2026.02 被 Anthropic 指控用虚假账户"蒸馏"Claude——引发了对中国 AI 公司训练数据来源的争议
百川智能
2023.04 由王小川(前搜狗 CEO)创立
2023 年快速迭代:7B(6 月)→ 13B(7 月)→ Baichuan2(9 月)
2024.01 Baichuan3,2024.05 Baichuan4
零一万物(01.AI)
2023.03 由李开复创立
2023.11 估值破 $10 亿(独角兽)
Yi-34B 在开源社区口碑不错
2024.05 发布万知(Wanzhi),对标 Copilot 的生产力助手
2025.03 停止预训练大模型——转向基于 DeepSeek 模型的企业解决方案。这是一个意味深长的信号:"做基础模型"的门槛越来越高,资本正在向头部集中
腾讯 · 混元
相对低调,主要服务于腾讯内部生态(微信、腾讯云、游戏)
技术实力扎实但不追求声量
商汤 · 日日新
视觉 AI 起家,在大模型时代继续聚焦多模态和视觉方向
中国大模型行业的独特逻辑
纵观中国大模型 3 年的发展,有几个独特的行业逻辑值得关注:
逻辑一:政策驱动——"备案"是第一关
中国的大模型应用需要向监管部门备案,获得批准后才能向公众开放。2023 年 8 月 31 日的首批备案是一个分水岭——获批的企业获得了先发优势。此后备案节奏成为影响竞争格局的重要因素。
逻辑二:价格战——中国特色的大模型竞争
2024 年 5 月,字节豆包大幅降价,触发行业价格战。中国大模型 API 的价格迅速降到美国同行的 1/10 甚至更低。这一方面降低了企业使用 AI 的门槛,另一方面也加速了中小玩家的出局——没有足够的资金支撑长期亏损,就只能退场。
逻辑三:"便宜+好用"取代"最强"成为用户选择标准
DeepSeek 和豆包的成功证明:对于大多数中国用户,"免费+够用"比"最强但贵"更有吸引力。这种用户偏好倒逼行业在成本优化上投入重注——DeepSeek 的极低训练成本是技术路线的胜利,也是市场需求的产物。
逻辑四:芯片禁令成了"反向激励"
美国对中国的芯片出口限制,本意是遏制中国的 AI 发展。但实际效果是:中国公司被迫在软件优化、架构创新、国产芯片适配等方面投入远超美国同行。DeepSeek 的极致效率、智谱的国产芯片训练、华为昇腾生态的加速——都是禁令"倒逼"的结果。
逻辑五:从"讲故事"到"看利润"——2025 年的资本变脸
2023 年,任何宣称做"中国版 ChatGPT"的公司都能融到钱。到 2025 年,投资人的问题从"你的模型参数多少"变成了"你的收入多少"。01.AI 停止预训练转向企业服务、多家公司裁员或合并——"百模大战"进入残酷的淘汰赛阶段。
中国大模型格局演变:
2023 群雄并起(100+ 家公司宣布做大模型)
↓
2024 牌桌形成(3巨头 + 6小虎 + 少量其他)
↓
2025 分化加速(DeepSeek/字节/阿里崛起,01.AI等退出基础模型竞争)
↓
2026 头部集中(3-5 家基础模型公司 + 大量应用层玩家)
附录:关键数字记忆
写在最后
这份大模型发展史写于 2026 年 5 月。从 2017 年的《Attention Is All You Need》到今天,不过 9 年。9 年前,没有人能预测到:八位工程师在 NeurIPS 上发表的一篇论文,会引发一场席卷全球每一个行业的技术革命。
这场革命远未结束。如果说过去 9 年是"让 AI 变聪明",接下来 10 年将是"让 AI 做事"。Agent、MCP、Agentic Engineering……这些概念指向同一个方向:AI 从"工具"变成"伙伴"——不仅理解你的意图,还能帮你执行。
而对于每一个身处这场变革中的人来说,Karpathy 的一句话可能是最好的导航:
"Code is cheap. Show me your talk."(代码不值钱,亮出你的思考。)
在 AI 时代,你的价值不在于你写了多少代码,而在于你如何思考、如何定义问题、如何做出判断。AI 可以生成一切——除了方向。而方向,永远来自人。
成文说明
本文由 刘小平(Xiaoping Liu) 使用 Hermes Agent(deepseek-v4-pro 模型) 完成。以下是完整的成文过程:
一、框架设计
阅读并分析用户提供的资料,从中提取 Karpathy 五阶段范式演进(Vibe Coding → Context Engineering → Spec Coding → Agentic Engineering)作为隐藏脉络的核心框架
基于对 LLM 发展史的先验知识,拟定"时间序主线 + 三条隐藏脉络(模型能力、工程方法、公众感知)"的双层叙事结构
产出《大模型发展历史·大纲》(存于同目录),经用户确认后进入写作
二、数据搜集
Wikipedia 检索:通过 curl 调用 Wikipedia API 的 action=query 端点,执行了 10+ 次结构化搜索——先用 list=search 定位相关页面,再用 prop=extracts 批量提取关键时间节点和背景信息。覆盖页面包括但不限于:ChatGPT、GPT-4、BERT、Claude、Gemini、DeepSeek、LLaMA、Ernie Bot、Qwen、Moonshot AI、Z.ai、MiniMax、01.AI、RLHF、Neural Scaling Law、RAG、OpenAI o1 等
并行检索:使用 delegate_task 将中国大模型信息和技术关键论文的搜索任务拆分为两个独立子 Agent,并行执行以提高效率
批量处理:用 execute_code 编写 Python 脚本批量调用 Wikipedia API、解析 JSON、提取日期关键句——将多次 API 调用的处理逻辑集中在一处执行,减少上下文往返
用户文档:已将用户上传资料全文读取作为领域知识注入上下文
三、写作与工具使用
大纲先行:先用 write_file 输出完整大纲(约 1,100 行 / 23KB),确立全局结构后再展开正文
全文生成:一次性生成终稿(约 1,100 行 / 68KB),减少分批次修补导致的风格不一致
结构化叙事:每个时间节点统一采用"事件描述 + 🔬⚙️👤 三维脉络标注"的格式;关键数据统一收入附录表格
ASCII 图表:使用文本框和 ASCII 流程图替代 Mermaid 等外部渲染,确保纯文本环境可读性
四、修订
初稿完成后,根据用户要求使用 patch 精确修改三处:第七阶段补充 DeepSeek V4 内容、DeepSeek 章节扩展 V3.1/V3.2/V4 迭代时间线、附录新增 V4 参数数据
修复脉络一能力跃迁图中因编辑导致的年份错位
五、数据可靠性说明
Wikipedia 在事件时间线、公司/产品背景、关键参数等事实性信息上具有较高的准确性和可核查性,但学术深度不及一手论文
推论性判断(如"公众感知""评价""技术趋势""行业逻辑")由模型基于多方信息综合形成,仅供参考与讨论
文中涉及的具体日期均已与 Wikipedia 交叉核对;参数数字(训练成本、参数规模、用户数等)以 Wikipedia 记录为准,部分为行业估计