

副标题:深入剖析 UUID 对 SQL 数据库的两大致命性能损耗以及对应策略
太长不看版,直接给结论:
1.使用uuidv7版本替换uuidv4,解决插入性能下降问题。
2.使用二进制BINARY(16)格式替换字符串格式进行存储,解决存储空间消耗问题。
在数据库设计中,UUID 字段常被用来唯一标识数据行。然而,这种做法伴随着一些你必须了解的性能隐患。本文就来聊聊,把 UUID 当作数据库表主键使用时,可能引发的两大性能问题。
UUID 是什么?
UUID 是通用唯一标识符(Universally Unique Identifier)的缩写。
UUID 有多个版本,通常我们使用的是 UUIDv4 版本,例如 hutool 工具自带的工具类方法 UUID.fastUUID() 即 UUIDv4 。
下面是一个 UUIDv4 的示例:
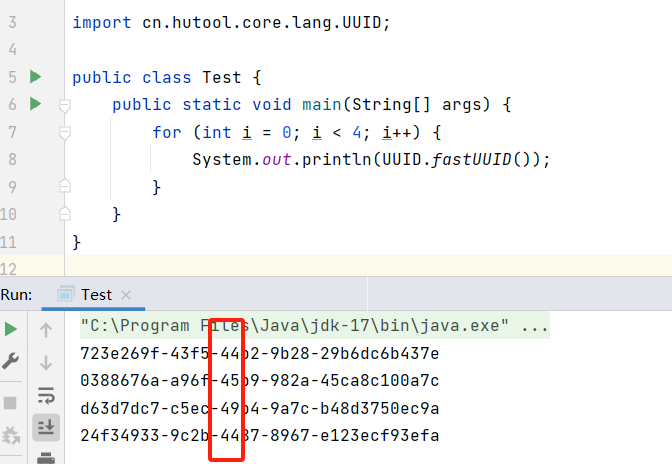
注意: 可以看到每个 UUIDv4 在第三组字符的第一位都是数字 4,用来标识版本。
问题一:插入性能下降
当新记录插入表中时,为了保证查询效率,与主键关联的索引也需要同步更新。
这些索引采用的是 B+ 树(B+ Tree)数据结构。
问题就出在 UUIDv4 上:
正是 UUID 本身的高度随机性,插入位置不确定,导致索引树频繁分裂和重组让 B+ 树的平衡变得困难重重。
破坏聚簇索引(如 InnoDB)的物理存储顺序,增加磁盘 I/O。
随着数据量增长到百万级别,需要重新平衡的节点数量激增,这将导致使用 UUID 主键时的插入性能显著下降。
问题二:存储开销增大
我们来比较一下大家常用的 varchar 格式的 UUID 和 BigInt 格式的自增整数(auto-incrementing integer)的大小。
BigInt 格式没有疑问,是固定长度的整数格式,它占用8个字节,也就是 64 位(bits)存储一个值。
标准 UUIDv4 格式:f47ac10b-58cc-4372-a567-0e02b2c3d479,总字符数36 个字符(32 个十六进制字符 + 4 个连字符 -)。
如不去掉 4 个连字符 ,那么 36 字符 × 8 bits/字符 = 288 bits,去掉则是 32 字符 × 8 bits/字符 = 256 bits。
加上varchar 字段类型的隐藏开销,数据库存储字符串时,会添加元数据(Metadata),以 MySQL InnoDB 为例:
实际场景中,VARCHAR(36) 存储 UUID 的平均总占用 ≈ 40 字节(即 320 bits),VARCHAR(32) 存储 UUID 的平均总占用 ≈ 36 字节(即 288 bits)
这意味着每行仅 ID 字段就多消耗 3.5 - 4 倍空间!
由于 UUID 通常是数据库主键,必然建立索引,存储空间增大会连带索引结构劣化、在数据写入、查询时的性能下降,就不展开讲了。
对策
引入UUIDv7
针对问题一:插入性能下降,我们可以使用 UUIDv7,UUIDv7 的革新性在于将时间戳嵌入最高有效位(Most Significant Bits),实现了全局单调递增。其 128 位结构如下:
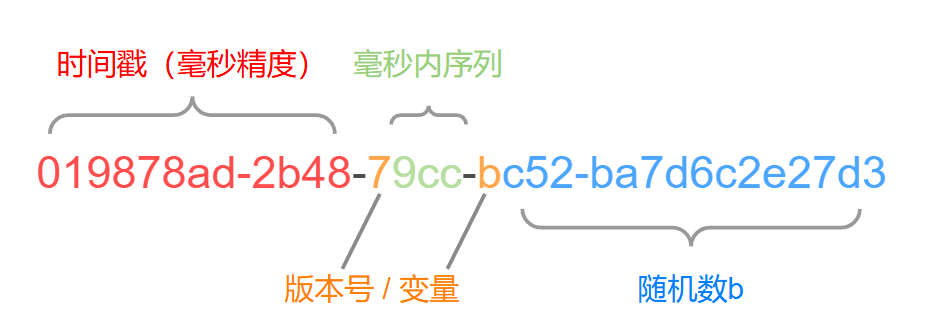
HuTool 并不支持 UUIDv7,我们需要引入一个新的工具包。
<dependency>
<groupId>com.github.f4b6a3</groupId>
<artifactId>uuid-creator</artifactId>
<version>6.1.1</version>
</dependency>使用
UuidCreator.getTimeOrderedEpoch();使用二进制BINARY(16)
针对问题二:存储开销增大,如果你使用 MySQL 数据库,可以通过BINARY(16)字段类型存储UUID来进行缓解。如果你使用 PostgreSQL 数据库,则直接使用 UUID 字段类型。
对比一下三种数据类型占用的存储空间(百万行数据)
可以看到使用了正确类型存储的 UUID 仅为 BigInt 两倍大小。
总结
当我们必须使用UUID来确保表中记录唯一时,我们要知道UUID有哪些坑,如何取其精华、去其糟粕,在数据库设计时做出最优选择。