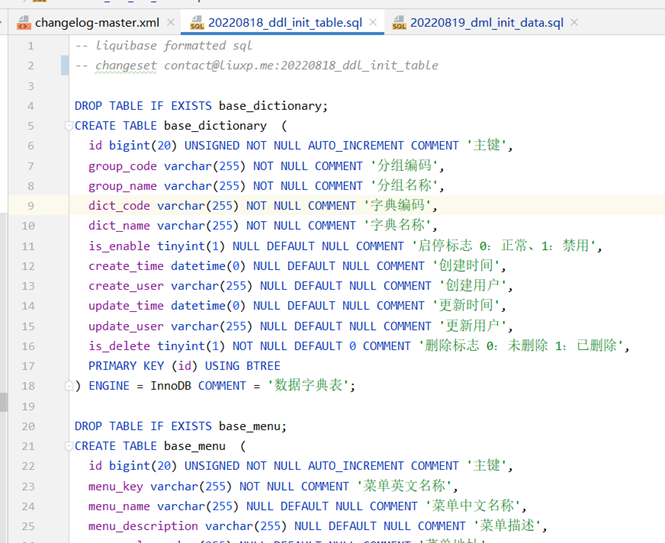
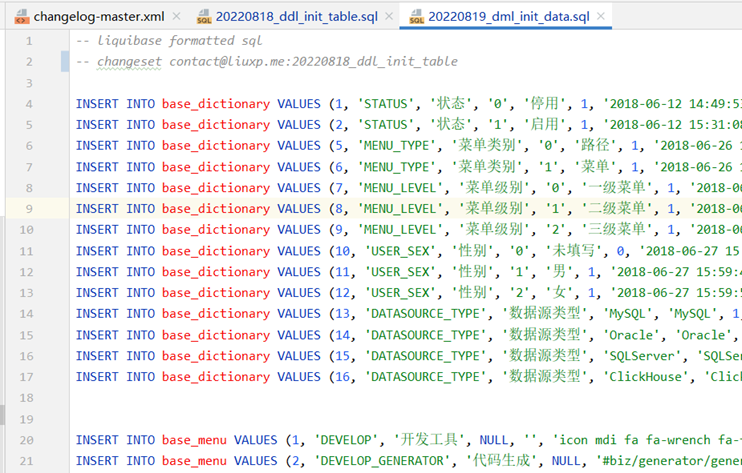
1.存储技术的背景
早些年,传统数据中心主要是烟囱式架构,系统扩展性较差加上过去硬盘容量偏小、价格偏高,企业主要用存储保存关键数据。
“烟囱式”系统,来自维基百科的解释是:一种不能与其他系统进行有效协调工作的信息系统,又称为孤岛系统。
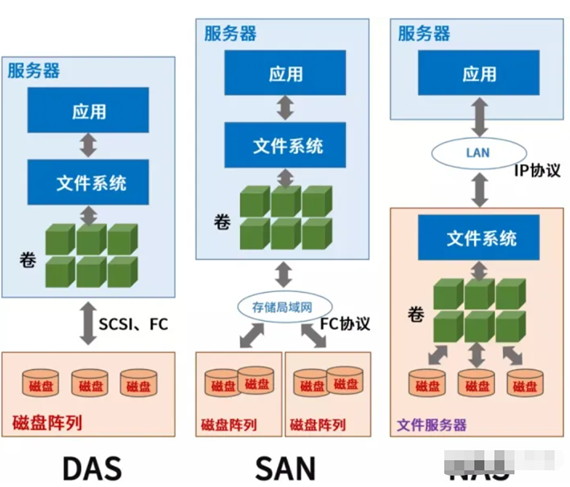
长久以来,这三种架构几乎统治了数据存储市场。所有行业用户的数据存储需求,都是在这三者中进行选择。
在新数据时代,传统数据中心向云计算、大数据、人工智能转变,越来越多的应用和企业在使用新的存储形态,“对象存储”这个词变得炙手可热。
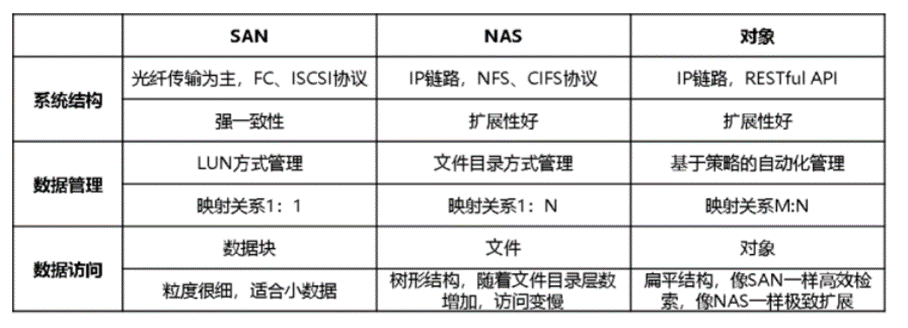
对比对象存储与SAN和NAS的差别,不难看出对象存储的核心优势所在:对象存储直接提供API给应用使用,采用扁平化的结构管理所有桶(Bucket)和对象。每个桶和对象都有一个全局唯一的ID,根据ID可快速实现对象的查找和数据的访问。
对象存储支持基于策略的自动化管理机制,使得每个应用可根据业务需要动态地控制每个桶的数据冗余策略、数据访问权限控制及数据生命周期管理。正是这些优势使得对象存储具备极致的扩展和极易的数据管理,在新数据时代如鱼得水。
2.MinIO特性介绍
MinIO 是一款高性能、分布式的对象存储系统。基于Golang编写。它是一款软件产品, 可以100%的运行在标准硬件。即X86等低成本机器也能够很好的运行MinIO。
MinIO与传统的存储和其他的对象存储不同的是:它一开始就针对性能要求更高的私有云标准进行软件架构设计。因为MinIO一开始就只为对象存储而设计。所以他采用了更易用的方式进行设计,它能实现对象存储所需要的全部功能,在性能上也更加强劲,它不会为了更多的业务功能而妥协,失去MinIO的易用性、高效性。 这样的结果所带来的好处是:它能够更简单的实现局有弹性伸缩能力的原生对象存储服务。
MinIO在传统对象存储用例(例如辅助存储,灾难恢复和归档)方面表现出色。同时,它在机器学习、大数据、私有云、混合云等方面的存储技术上也独树一帜。当然,也不排除数据分析、高性能应用负载、原生云的支持。
在中国:阿里巴巴、腾讯、百度、中国联通、华为、中国移动等等9000多家企业也都在使用MinIO产品。
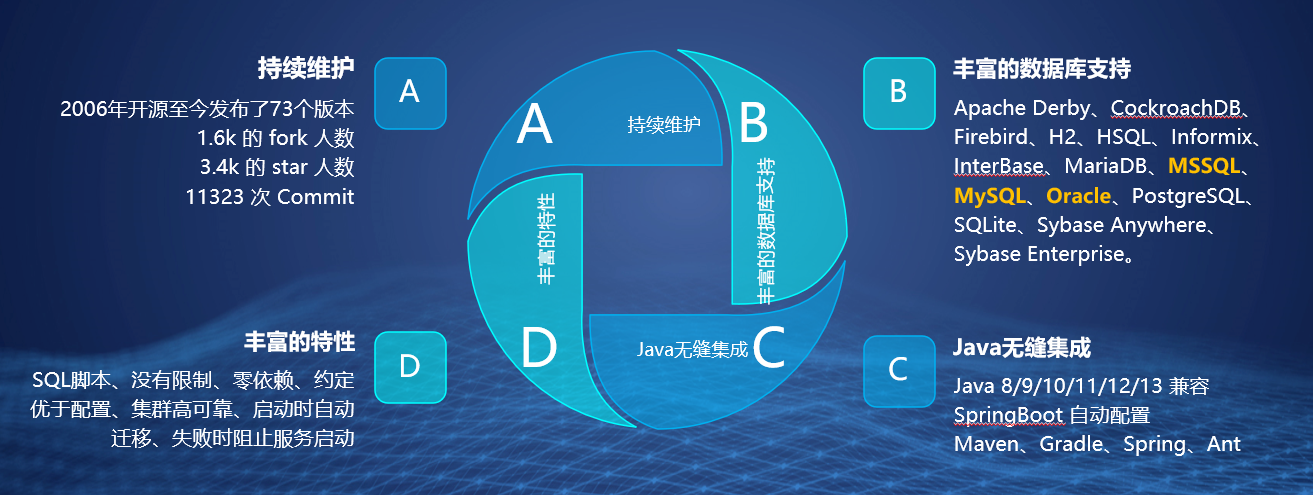
2.1成长性
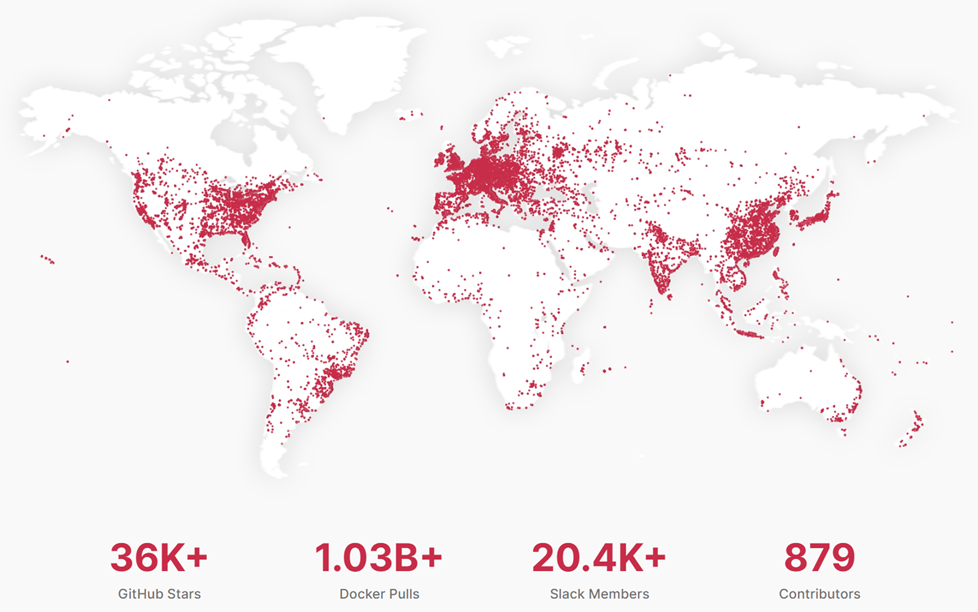
成长最快的对象存储系统
GiHub Stars 36.1k,Docker镜像拉取数量 1.03B,群组成员 20.4k,贡献者 879人。
2.2同步、拷贝
主动、多节点复制是对象存储关键指标。
MinIO提供桶级粒度,并支持同步和近同步复制,这取决于体系结构的选择和数据的变化率。
2.3数据管理
数据是企业最关键的资产,因此必须在整个组织中方便、安全地提供数据,以便使其对每个人的价值最大化。因此,企业必须根据用户的需求采用一系列数据接口方法。
MinIO提供了一套标准接口,可以覆盖数据驱动企业中的每个角色,比如图形用户界面(GUI)、命令行界面(CLI)和应用程序编程接口(API)。
2.4加密
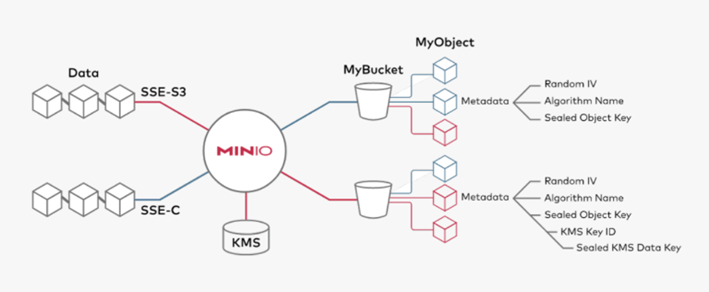
MinIO提供了高强度的加密算法并做了大量性能优化,几乎消除了存储加密操作相关性能的开销。
MinIO支持多种复杂的服务器端加密方案,以保护数据-无论其位于何处。
MinIO的方法可确保机密性,完整性和真实性,而性能开销却可以忽略不计。 使用AES-256-GCM,ChaCha20-Poly1305和AES-CBC支持服务器端和客户端加密。加密的对象使用AEAD服务器端加密进行了防篡改。此外,MinIO与所有常用的密钥管理解决方案(例如HashiCorp Vault)兼容并经过测试
MinIO使用密钥管理系统(KMS)支持SSE-S3。如果客户端请求SSE-S3,或启用了自动加密,则MinIO服务器会使用唯一的对象密钥对每个对象进行加密,该对象密钥受KMS管理的主密钥保护。由于开销极低,因此可以为每个应用程序和实例打开自动加密。
2.5安全
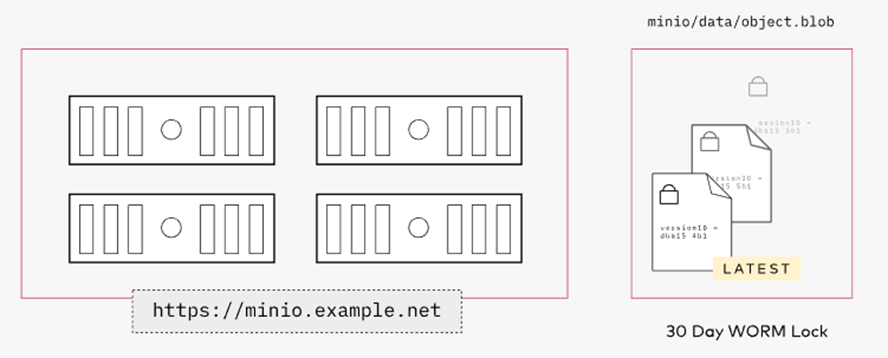
桶和对象的不可修改
保护数据不被删除(意外或故意)是涉及每个行业的关键合规组件。
MinIO支持一系列完整的功能,包括对象锁定、保留、合法保持、治理和遵从性。
MinIO的桶和对象不变性是由Cohasset Partners根据SEC规则17a-4(f)、FINRA规则4511和CFTC规则1.31进行Veeam认证和验证的。
2.6部署支持
支持多种部署环境:Kubernetes、Docker、Linux、macOS、Windows。
3.安装
3.1 Linux 安装部署
3.1.1 下载 MinIO 的 linux 版本安装包
https://min.io/download#/linux
3.1.2 上传安装包
复制到 CentOS7 服务器 /opt/minio 路径下
3.1.3 创建数据目录
mkdir /data/minioadduser miniochown minio:minio /data/miniochown minio:minio /data/minio/*chmod -R 777 /data/minio
3.1.4 安装执行文件复制到bin目录
chmod +x /opt/minio/miniomv minio /usr/local/bin
3.1.5 设置服务配置文件
新建/usr/lib/systemd/system/minio.service
[Unit]Description=Minio ServerDocumentation=https://docs.minio.ioAfter=network.target[Service]User=minioGroup=minioPermissionsStartOnly=trueEnvironmentFile=-/etc/minio.confExecStartPre=/bin/bash -c "[ -n \"${MINIO_VOLUMES}\" ] || echo \"Variable MINIO_VOLUMES not set in /etc/minio.conf\""ExecStart=/usr/local/bin/minio server $MINIO_OPTS $MINIO_VOLUMESStandardOutput=journalStandardError=inherit# Specifies the maximum file descriptor number that can be opened by this processLimitNOFILE=65536# Disable timeout logic and wait until process is stoppedTimeoutStopSec=0# SIGTERM signal is used to stop MinioKillSignal=SIGTERMSendSIGKILL=noSuccessExitStatus=0[Install]WantedBy=multi-user.target
3.1.6 设置Minio配置文件
新建 /etc/minio.conf
MINIO_ACCESS_KEY=rootMINIO_SECRET_KEY=Viewhigh*132MINIO_VOLUMES="/data/minio/"MINIO_OPTS="--address :9000"
3.1.7 重新加载系统配置
systemctl daemon-reloadsystemctl start minio
3.1.8 开放端口
防火墙开放9000端口
firewall-cmd --zone=public --add-port=9000/tcp --permanentfirewall-cmd --reload
3.1.9 设置服务自启动
systemctl enable minio
3.1.10 验证
浏览器访问:http://127.0.0.1:9000
账号/密码:root/Viewhigh*132。
3.2 Windows 安装部署
3.2.1 下载
打开MinIO官网,网址:https://www.minio.org.cn/ 点击版本归档,点击server/minio/release/windows-amd64/minio.exe开始下载。
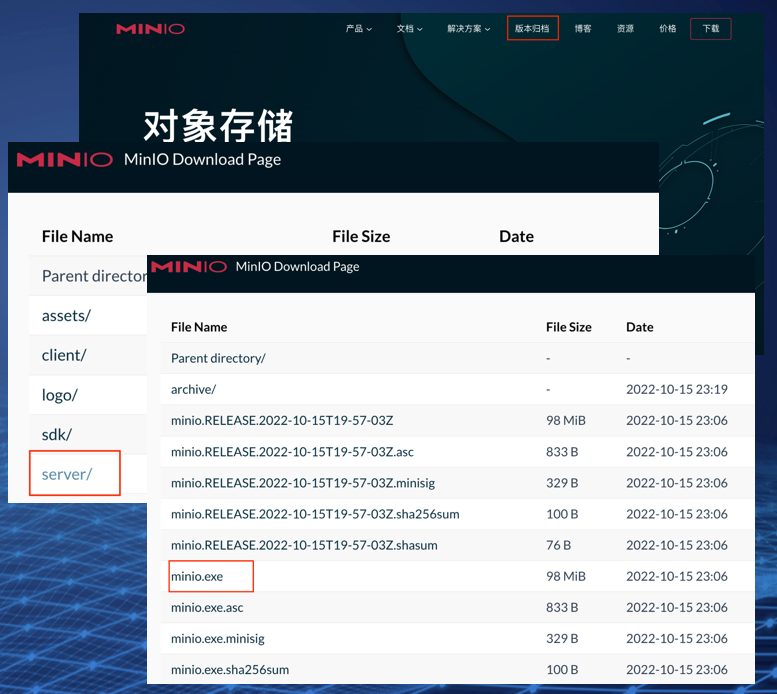
3.2.2 安装
在E:\Program Files\下,新建目录minio,在minio下新建data目录。将下载的minio.exe,拷贝到目录:E:\Program Files\minio\,如下图。
注意:安装目录根据实际需要新建。
3.2.3 运行
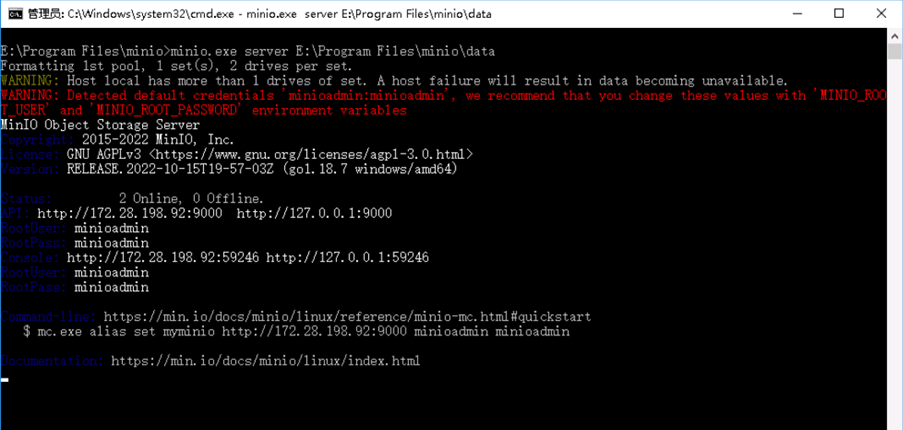
打开cmd命令行,进入到minio.exe所在的目录。输入命令: minio.exe server E:\Program Files\minio\data
server后面的地址是文件上传之后的存储目录。
出现以下界面,说明minio启动成功。
3.2.4 登录验证
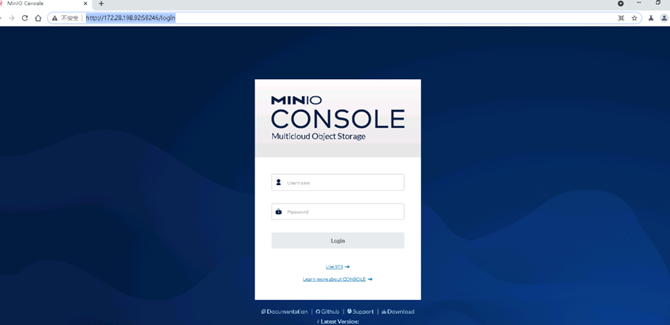
打开浏览器,输入http://127.0.0.1:9000/login,打开以下页面,说明minio启动成功。
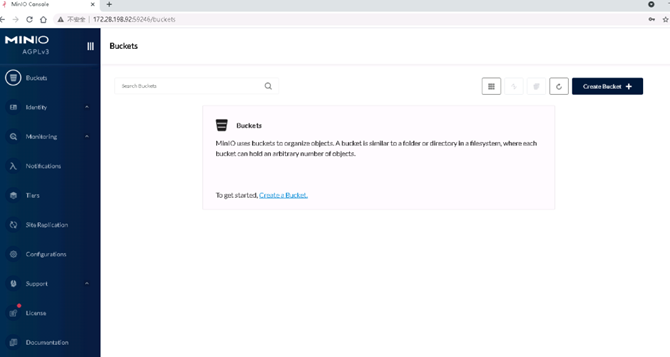
输入用户名和密码:minioadmin/minioadmin,点击登录。打开如下页面,说明minio成功安装,并正常运行。
3.2.5 配置
目前minio用的还是默认的帐号密码,我们需要修改为自己需要的帐号和密码。关闭minio,按照以下步骤操作:
- 打开cmd命令行,进入到minio.exe所在的目录。
- 输入set MINIO_ACCESS_KEY=gov_cloud,修改ACCESS-KEY为gov_cloud。
- 输入set MINIO_SECRET_KEY=viewhigh,修改 SECRET-KEY为viewhigh。
- 输入minio.exe server E:\Program Files\minio\data,重新启动minio。
至此,密码修改完成。
如果要修改端口的话,可以用以下命令:
minio.exe --address :9000 server E:\Program Files\minio\data
在E:\Program Files\minio目录,新建run.bat文件,内容如下:
set MINIO_ACCESS_KEY=gov_cloudset MINIO_SECRET_KEY=viewhighminio.exe server E:\Program Files\minio\data
以后可以点击bat文件直接运行。
4.使用
4.1 Java工程集成
4.1.1 添加依赖
以maven配置为例,直接引用即可。
<dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.2.0</version></dependency>
4.1.2 配置地址
配置我们之前安装好的MinIO服务地址和登录用户。
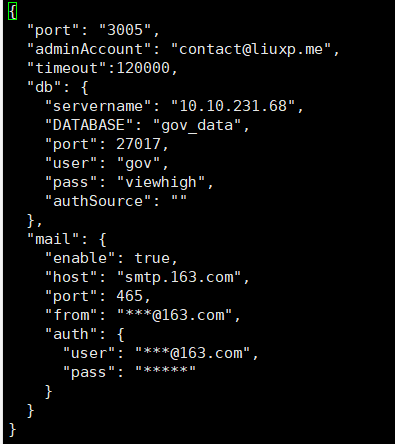
################################################################### 文件存储##################################################################minio: url: http://10.10.231.68:9000 key: gov_cloud secret: viewhigh bucket: infra-storage
经过以上非常简单的两步操作,我们就将MinIO集成到我们的Java工程中了。
4.2 Java代码中使用
这里给大家提供一个简单的写入文件和读取文件的代码示例:
package com.vh.data.operation.report.report.storage.impl;import com.vh.data.operation.report.report.storage.FileStorage;import com.vh.data.operation.report.report.storage.exception.FileStorageException;import io.minio.*;import org.apache.commons.io.IOUtils;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Value;import org.springframework.stereotype.Component;import java.io.ByteArrayInputStream;import java.io.ByteArrayOutputStream;import java.io.InputStream;import java.io.OutputStream;import java.util.HashMap;import java.util.Map;/** * Minio文件存储 */@Componentpublic class MinioFileStorage implements FileStorage { private Logger logger = LoggerFactory.getLogger(getClass()); private static final int DEFAULT_BUFFER_SIZE = 1024 * 1024; @Value("${minio.url}") private String minioUrl; @Value("${minio.key}") private String minioKey; @Value("${minio.secret}") private String minioSecret; @Value("${minio.bucket}") private String minioBucket; private MinioClient client; @Override public int writeFile(InputStream inputStream, String key, String contentType) { try (ByteArrayOutputStream bao = new ByteArrayOutputStream()) { MinioClient client = this.getClient(); // 检查存储桶是否已经存在 boolean isExist = client.bucketExists(BucketExistsArgs.builder().bucket(minioBucket).build()); if (!isExist) { // 创建存储桶。 client.makeBucket(MakeBucketArgs.builder().bucket(minioBucket).build()); } // 读取输入流到内存中 byte[] buff = new byte[DEFAULT_BUFFER_SIZE]; int bytesRead; while ((bytesRead = inputStream.read(buff)) != -1) { bao.write(buff, 0, bytesRead); } byte[] data = bao.toByteArray(); ByteArrayInputStream bin = new ByteArrayInputStream(data); // 使用putObject上传一个文件到存储桶中。 this.getClient().putObject(PutObjectArgs.builder() .bucket(minioBucket) .object(key) .stream(bin, bin.available(), 0L) .contentType(contentType) .build()); return data.length; } catch (Exception e) { throw new FileStorageException(e); } } @Override public void readFile(OutputStream outputStream, String key) { long startTime = System.currentTimeMillis(); logger.info("开始读取文件:" + key); // 客户端 MinioClient client = this.getClient(); // 文件流 try (InputStream is = client.getObject(GetObjectArgs.builder().bucket(minioBucket).object(key).build())) { IOUtils.copy(is, outputStream); } catch (Exception e) { logger.error("IO异常:" + e.getMessage(), e); throw new FileStorageException(e); } logger.info("结束读取文件:" + key + ",耗时:" + (System.currentTimeMillis() - startTime) / 1000); } private MinioClient getClient() { if (client != null) { return client; } return createClient(); } private synchronized MinioClient createClient() { if (client != null) { return client; } // 创建客户端 client = new MinioClient .Builder() .endpoint(minioUrl) .credentials(minioKey, minioSecret) .build(); return client; }}
4.3 在MinIO后台页面管理文件
除了在Java中使用以外,我们还可以非常方便的在MinIO后台页面进行文件管理。
在后台管理页面,可以创建删除桶。
可以创建、删除目录。
可以上传、下载、删除文件。
可以创建文件的直读分享链接。
5.总结
MinIO是一个部署简单,性能强大,易于使用的对象存储项目。
希望这篇文章能够帮助到大家。
6. 参考资料
]]>